Visibility of end-user experience over networks is challenging, particularly as applications are further distributed.
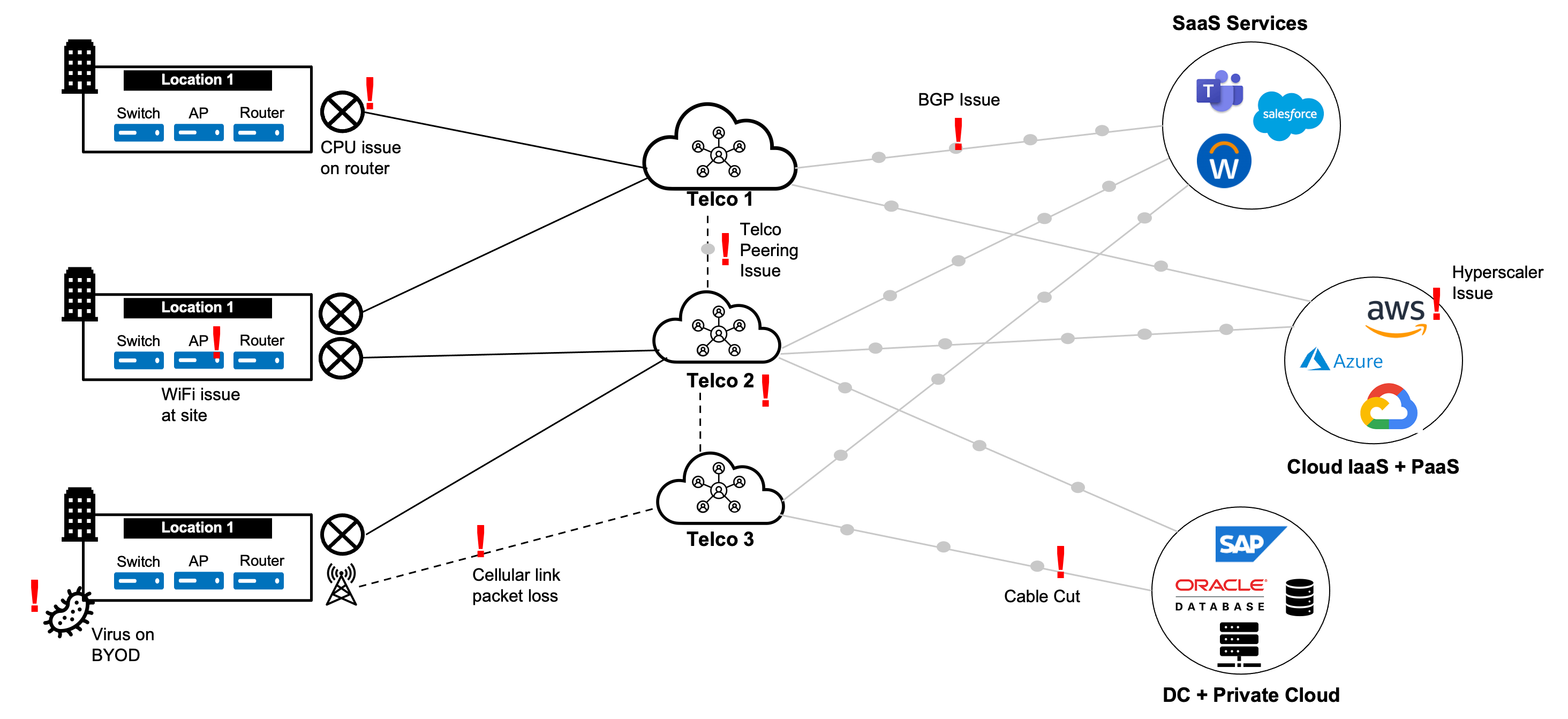
Networks’ current and future state relies on a better approach to network observability and intelligence.
There are many network observability products, but not enough insight. Why?
Service Experience Insights are a way for clients to continuously monitor how their users experience accessing key business-critical applications – whether they are in the Cloud or on-premise – from multiple locations on their network.
Service Experience Insights supports the following key use cases;
Service Experience Insights are then combined with network metric information to provide a holistic view of network health and user experience to clients.
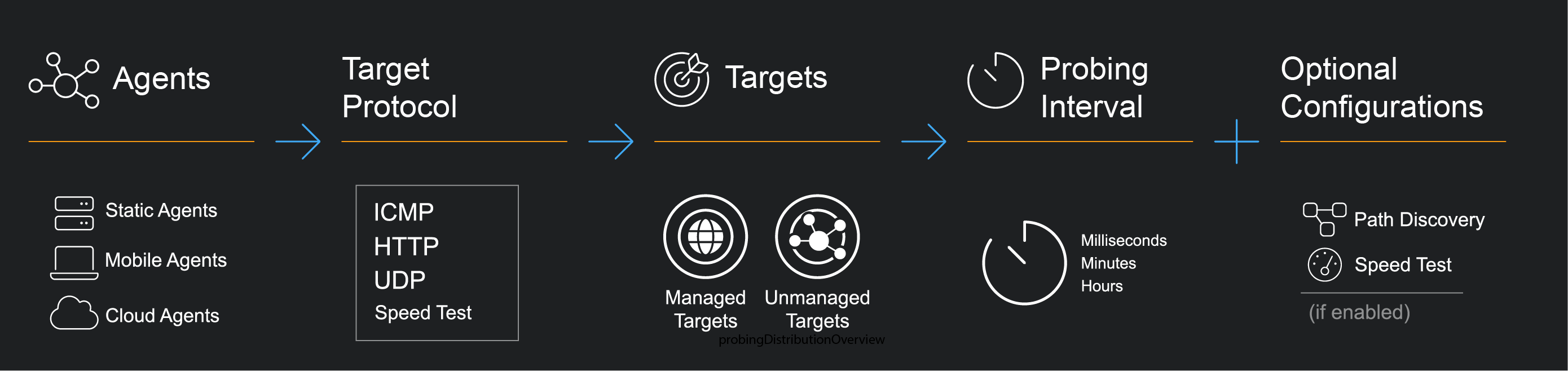
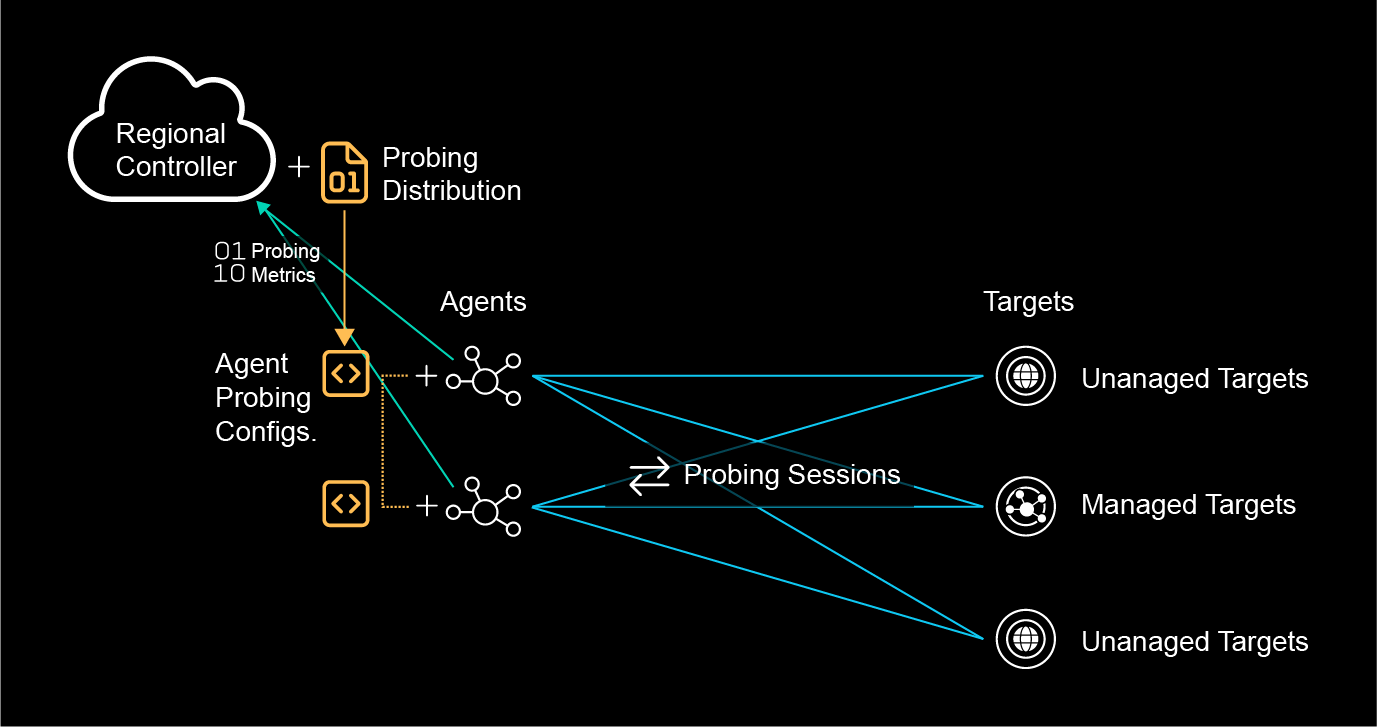
Service Experience Insights provides an easy-to-deploy flexible system for continuous monitoring between agents and targets.
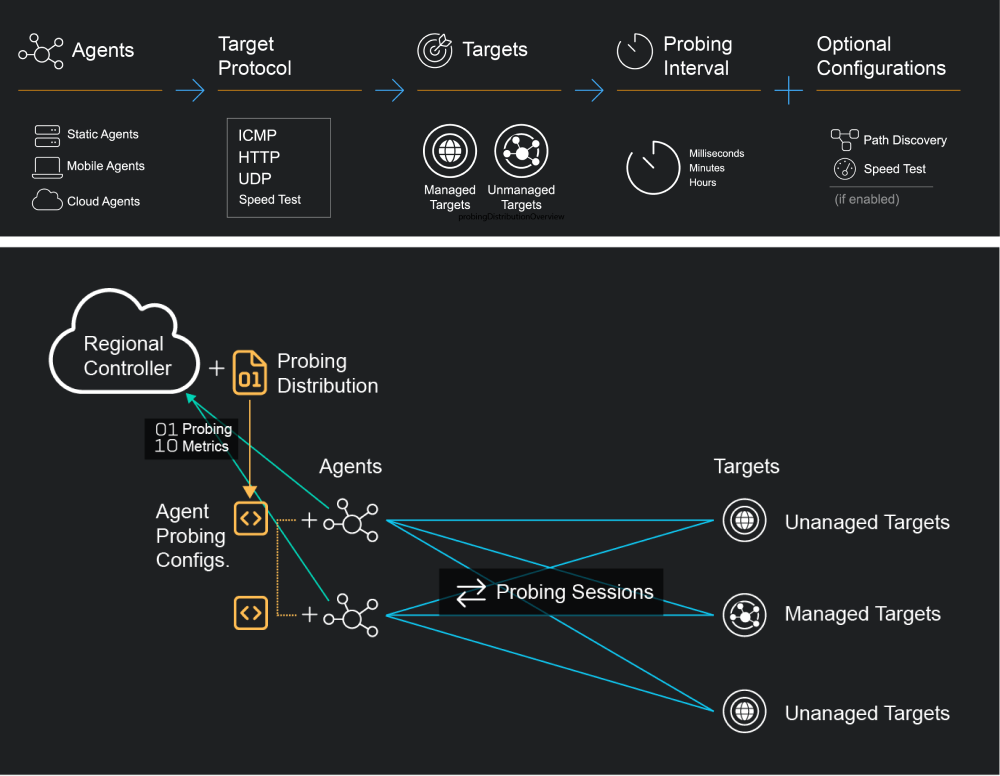
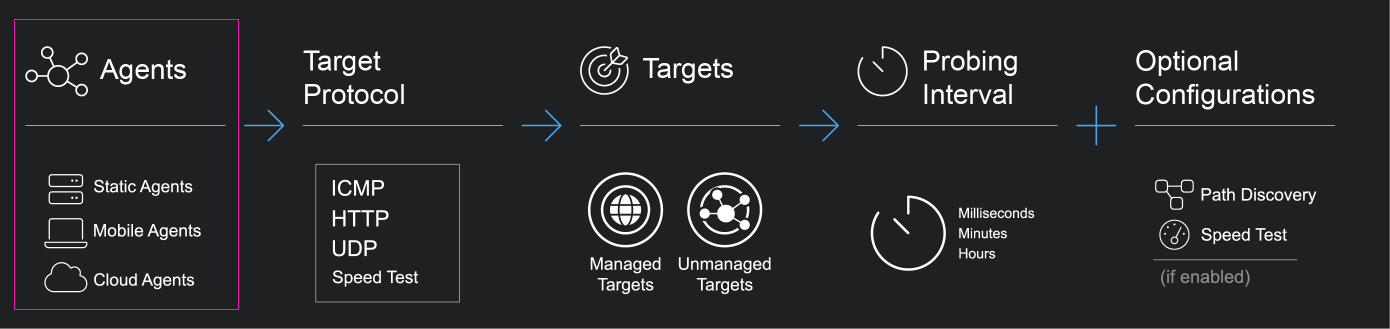
Agents are lightweight probing software that can be configured to send synthetic probing traffic to internet endpoints and other agents in order to monitor the quality of network traffic to business-critical services continuously.
The agent is configured to periodically send synthetic probing traffic to internet endpoints and other agents within the network. This synthetic traffic mimics the behavior of actual network traffic and is used to test the quality and performance of the network. By sending synthetic traffic, the agent can detect any issues with the network before they become critical problems.
A variety of agent software is provided to support deployment in heterogeneous network environments.
For dedicated network devices
SPEKTRA Edge appliances and deployed to generic devices running EdgeLQ OS.
For application-hosting network appliances
Deploy in Docker containers to Cisco 9K series application-hosting routers and switches.
For data centers and cloud environments
Deploy to VMs with Docker runtime hosted in public or private cloud environments.
For mobile end-user devices
Deploy as native applications on Windows and macOS – Self Installation and Endpoint Management Supported.
The agent can be configured to send different ICMP, HTTP, UDP, and Speed Test synthetic traffic. This allows the agent to simulate different types of network traffic and to test various aspects of the network, such as latency, packet loss, bandwidth, and throughput.
The agent can be configured to send synthetic traffic to specific endpoints or hosts within the network, such as business-critical services or servers. This allows the agent to monitor the performance of these services and to detect any issues that may impact the availability or quality of the service. The agent can also be configured to send synthetic traffic to external endpoints, such as public websites or cloud services. This allows the agent to monitor the performance of external services that may impact the network’s performance, such as cloud applications or third-party services.
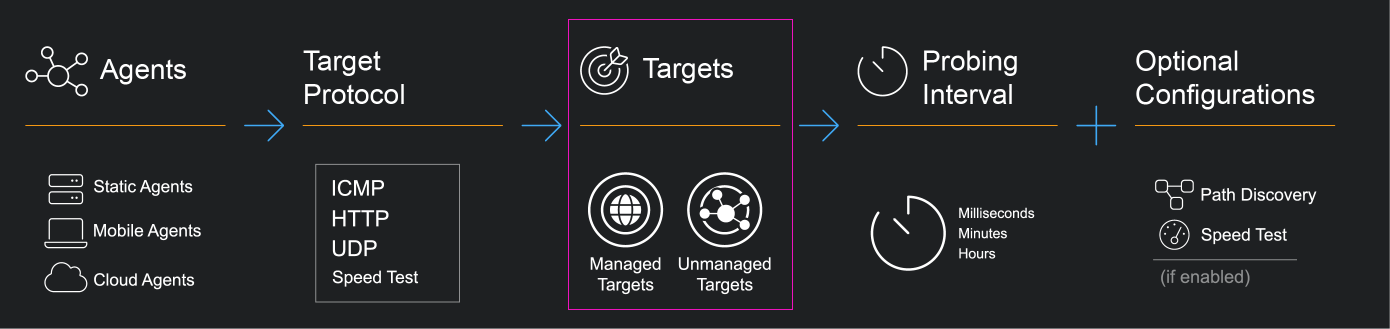
Service Experience Insight supports Unmanaged Targets and Managed Targets.
| ICMP | HTTP | UDP | Speed Test | ||
|---|---|---|---|---|---|
| Unmanaged Targets | -- | ||||
| Managed Targets | -- | ||||
| ICMP | HTTP | UDP | Speed Test | ||
|---|---|---|---|---|---|
| Latency (ms) | -- | ||||
| Jitter (ms) | -- | ||||
| Loss (%) | -- | -- | |||
| HTTP Availability (%) | -- | -- | -- | ||
| HTTP Request Response Time (ms) | -- | -- | -- | ||
| Connection set up | DNS lookup (ms) | -- | -- | -- | |
| Initial connection (ms) | -- | -- | -- | ||
| SSL (ms) | -- | -- | -- | ||
| Request Response | Request Send (ms) | -- | -- | -- | |
| Waiting TTFB (ms) | -- | -- | -- | ||
| Content Download (ms) | -- | -- | -- | ||
| Hops Latency (ms) | -- | ||||
| Probing Interval Default | 30 seconds | 60 seconds | 30 seconds | 1 hour | |
| Probing Interval Custom | 1 sec. to 10 min. | 30 sec. to 10 min. | 100 millisec. to 10 min. | 1, 6, 12, 24 hrs. | |
| Probing Duration | NA | NA | NA | 3, 8, or 10 sec. | |
Probing Distributions are configurable policies for triggering synthetic monitoring traffic between agents and targets.
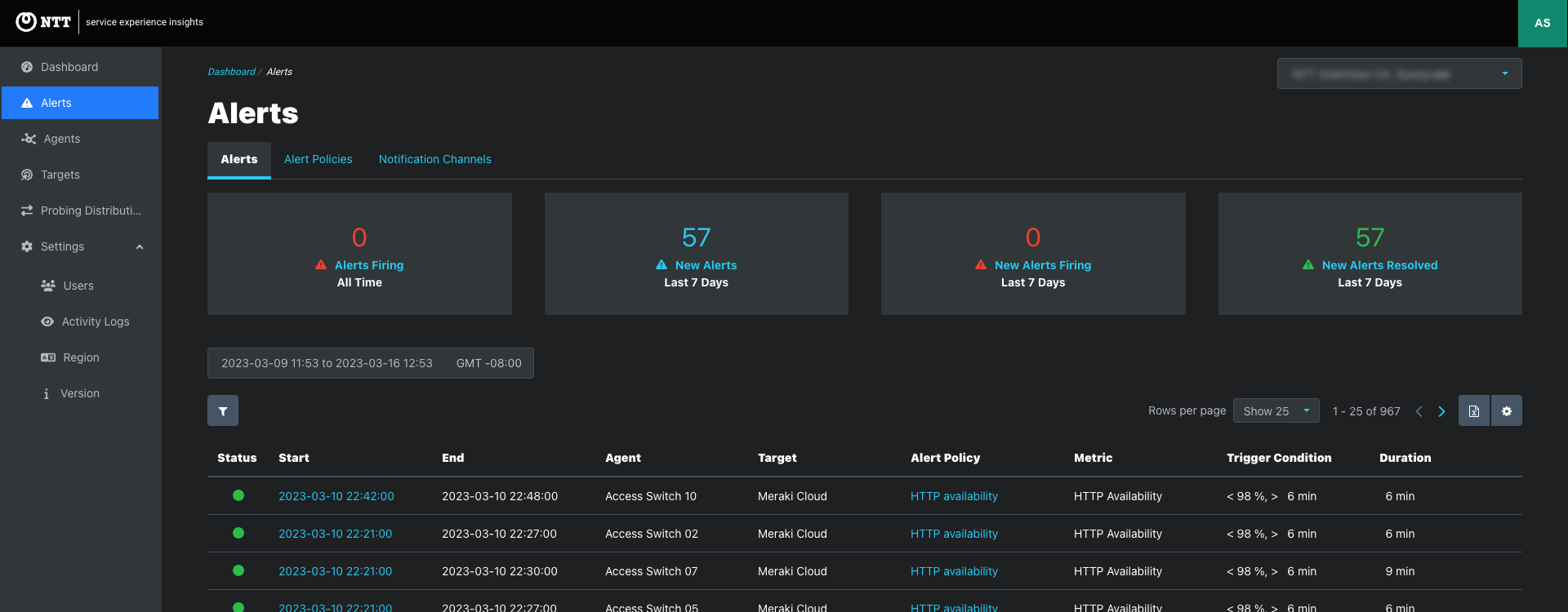
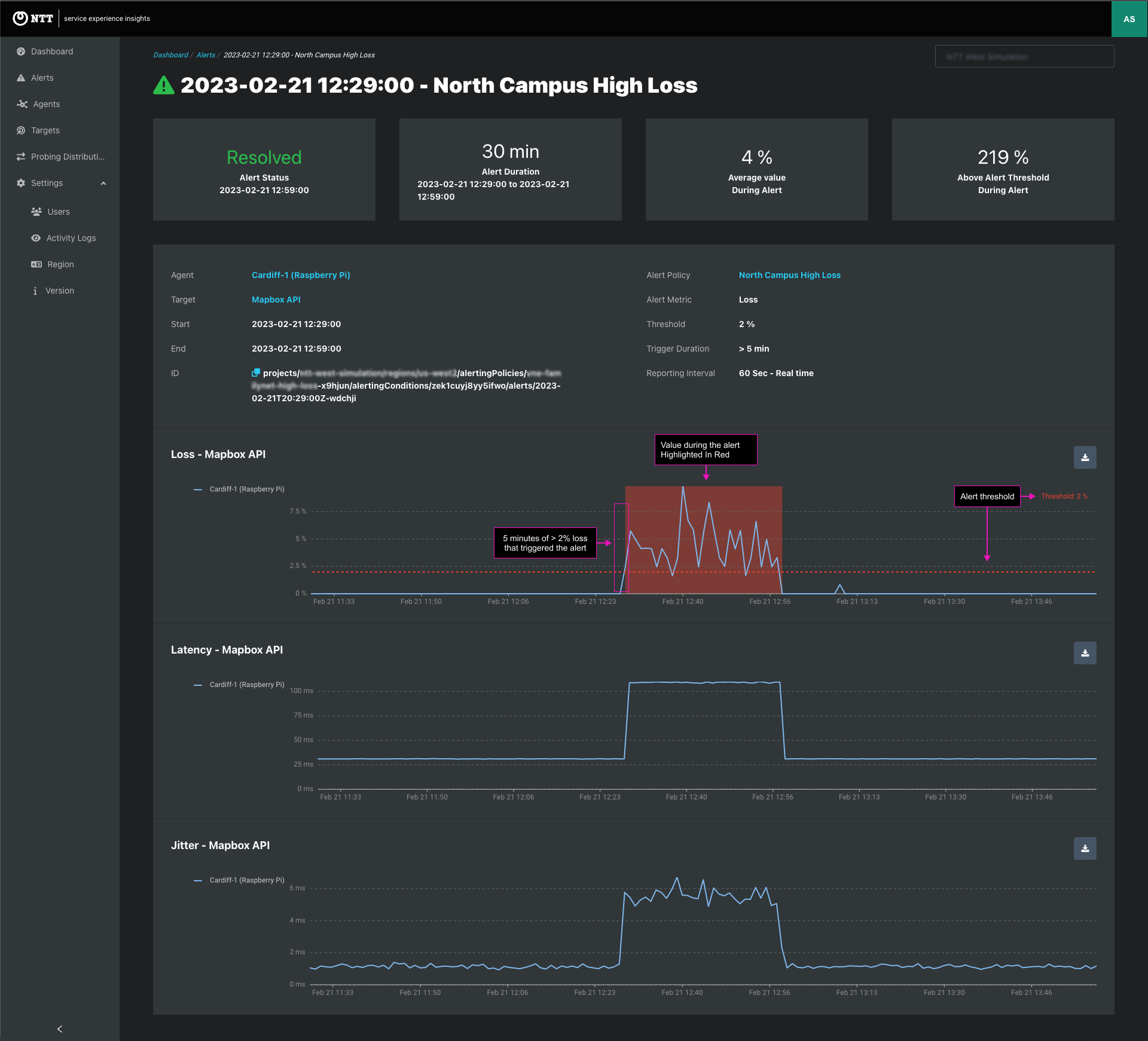
User management enables Admins and Co-admins to manage user access to each project.